Scheduling¶
Most data sources aren't sitting idle: they steadily generate new data. To keep up with new information, we can utilize a schedule manager (or even the simplest while-loop) to periodically run jobs related to data capturing and manipulation.
Updating¶
We can schedule data updates easily using DataUpdater, which takes a data instance of type Data and a schedule manager of type ScheduleManager, and periodically triggers an update that replaces the old data instance with the new one. We can then access the new instance under DataUpdater.data. The update happens in the method DataUpdater.update, which can be overridden and used to run some custom logic when new data arrives. Since the updater class subclasses Configured, it also takes care of replacing its config once data changes.
Important
It's one of the few classes in vectorbt that aren't read-only. Do not rely on caching inside it!
Let's use this simple but powerful class to update and plot the last 10 minutes of a Binance ticker, every 10 seconds, for 5 minutes. First, we will pull the latest 10 minutes of data:
>>> from vectorbtpro import *
>>> data = vbt.BinanceData.pull(
... "BTCUSDT",
... start="10 minutes ago UTC",
... end="now UTC",
... timeframe="1m"
... )
>>> data.close
Open time
2022-02-19 20:09:00+00:00 40005.78
2022-02-19 20:10:00+00:00 40001.80
2022-02-19 20:11:00+00:00 40006.45
2022-02-19 20:12:00+00:00 40003.68
2022-02-19 20:13:00+00:00 40022.24
2022-02-19 20:14:00+00:00 40026.73
2022-02-19 20:15:00+00:00 40048.88
2022-02-19 20:16:00+00:00 40044.92
2022-02-19 20:17:00+00:00 40044.03
2022-02-19 20:18:00+00:00 40049.93
Freq: T, Name: Close, dtype: float64
Then, we'll subclass DataUpdater to accept the figure and update it together with the data. Moreover, to not miss anything visually, after each update, we will append the figure's PNG image to a GIF file:
>>> import imageio.v2 as imageio
>>> class OHLCFigUpdater(vbt.DataUpdater):
... _expected_keys = None
...
... def __init__(self, data, fig, writer=None, display_last=None,
... stop_after=None, **kwargs):
... vbt.DataUpdater.__init__( # (1)!
... self,
... data,
... writer=writer, # (2)!
... display_last=display_last,
... stop_after=stop_after,
... **kwargs
... )
...
... self._fig = fig
... self._writer = writer
... self._display_last = display_last
... self._stop_after = stop_after
... self._start_dt = vbt.utc_datetime() # (3)!
...
... @property # (4)!
... def fig(self):
... return self._fig
...
... @property
... def writer(self):
... return self._writer
...
... @property
... def display_last(self):
... return self._display_last
...
... @property
... def stop_after(self):
... return self._stop_after
...
... @property
... def start_dt(self):
... return self._start_dt
...
... def update(self, **kwargs):
... vbt.DataUpdater.update(self, **kwargs) # (5)!
...
... df = self.data.get()
... if self.display_last is not None:
... df = df[df.index[-1] - self.display_last:] # (6)!
...
... trace = self.fig.data[0]
... with self.fig.batch_update():
... trace.x = df["Close"].index # (7)!
... trace.open = df["Open"].values
... trace.high = df["High"].values
... trace.low = df["Low"].values
... trace.close = df["Close"].values
...
... if self.writer is not None:
... fig_data = imageio.imread(self.fig.to_image(format="png"))
... self.writer.append_data(fig_data) # (8)!
...
... if self.stop_after is not None:
... now_dt = vbt.utc_datetime()
... if now_dt - self.start_dt >= self.stop_after:
... raise vbt.CancelledError # (9)!
- Call the constructor of
DataUpdater - Pass all class-specific keyword arguments to include them in the config
- Register the start time
- Properties prevent the user (and the program) from overwriting the object, which is some kind of convention in vectorbt
- Call
DataUpdater.update, otherwise, the data won't update! - Get the OHLC data within a specific time period (optional)
- Update the data of the trace (see Candlestick Charts)
- Append the data of the figure to the GIF file (optional)
- Stop once the job has run for a specific amount of time by throwing CancelledError (optional)
Don't forget to enable logging (if desirable):
Finally, run the job of OHLCFigUpdater every 10 seconds:
>>> fig = data.plot(ohlc_type="candlestick", plot_volume=False)
>>> fig # (1)!
>>> with imageio.get_writer("ohlc_fig_updater.gif", duration=250, loop=0) as writer: # (2)!
... ohlc_fig_updater = OHLCFigUpdater(
... data=data,
... fig=fig,
... writer=writer,
... display_last=pd.Timedelta(minutes=10),
... stop_after=pd.Timedelta(minutes=5)
... )
... ohlc_fig_updater.update_every(10) # (3)!
INFO:vectorbtpro.utils.schedule_:Starting schedule manager with jobs [Every 10 seconds do update() (last run: [never], next run: 2022-02-19 21:18:38)]
INFO:vectorbtpro.data.updater:New data has 10 rows from 2022-02-19 20:09:00+00:00 to 2022-02-19 20:18:00+00:00
INFO:vectorbtpro.data.updater:New data has 10 rows from 2022-02-19 20:09:00+00:00 to 2022-02-19 20:18:00+00:00
INFO:vectorbtpro.data.updater:New data has 11 rows from 2022-02-19 20:09:00+00:00 to 2022-02-19 20:19:00+00:00
INFO:vectorbtpro.data.updater:New data has 11 rows from 2022-02-19 20:09:00+00:00 to 2022-02-19 20:19:00+00:00
INFO:vectorbtpro.data.updater:New data has 11 rows from 2022-02-19 20:09:00+00:00 to 2022-02-19 20:19:00+00:00
INFO:vectorbtpro.data.updater:New data has 11 rows from 2022-02-19 20:09:00+00:00 to 2022-02-19 20:19:00+00:00
INFO:vectorbtpro.data.updater:New data has 11 rows from 2022-02-19 20:09:00+00:00 to 2022-02-19 20:19:00+00:00
INFO:vectorbtpro.data.updater:New data has 12 rows from 2022-02-19 20:09:00+00:00 to 2022-02-19 20:20:00+00:00
INFO:vectorbtpro.data.updater:New data has 12 rows from 2022-02-19 20:09:00+00:00 to 2022-02-19 20:20:00+00:00
INFO:vectorbtpro.data.updater:New data has 12 rows from 2022-02-19 20:09:00+00:00 to 2022-02-19 20:20:00+00:00
INFO:vectorbtpro.data.updater:New data has 12 rows from 2022-02-19 20:09:00+00:00 to 2022-02-19 20:20:00+00:00
INFO:vectorbtpro.data.updater:New data has 12 rows from 2022-02-19 20:09:00+00:00 to 2022-02-19 20:20:00+00:00
INFO:vectorbtpro.data.updater:New data has 13 rows from 2022-02-19 20:09:00+00:00 to 2022-02-19 20:21:00+00:00
INFO:vectorbtpro.data.updater:New data has 13 rows from 2022-02-19 20:09:00+00:00 to 2022-02-19 20:21:00+00:00
INFO:vectorbtpro.data.updater:New data has 13 rows from 2022-02-19 20:09:00+00:00 to 2022-02-19 20:21:00+00:00
INFO:vectorbtpro.data.updater:New data has 13 rows from 2022-02-19 20:09:00+00:00 to 2022-02-19 20:21:00+00:00
INFO:vectorbtpro.data.updater:New data has 13 rows from 2022-02-19 20:09:00+00:00 to 2022-02-19 20:21:00+00:00
INFO:vectorbtpro.data.updater:New data has 14 rows from 2022-02-19 20:09:00+00:00 to 2022-02-19 20:22:00+00:00
INFO:vectorbtpro.data.updater:New data has 14 rows from 2022-02-19 20:09:00+00:00 to 2022-02-19 20:22:00+00:00
INFO:vectorbtpro.data.updater:New data has 14 rows from 2022-02-19 20:09:00+00:00 to 2022-02-19 20:22:00+00:00
INFO:vectorbtpro.data.updater:New data has 14 rows from 2022-02-19 20:09:00+00:00 to 2022-02-19 20:22:00+00:00
INFO:vectorbtpro.data.updater:New data has 14 rows from 2022-02-19 20:09:00+00:00 to 2022-02-19 20:22:00+00:00
INFO:vectorbtpro.data.updater:New data has 15 rows from 2022-02-19 20:09:00+00:00 to 2022-02-19 20:23:00+00:00
INFO:vectorbtpro.data.updater:New data has 15 rows from 2022-02-19 20:09:00+00:00 to 2022-02-19 20:23:00+00:00
INFO:vectorbtpro.data.updater:New data has 15 rows from 2022-02-19 20:09:00+00:00 to 2022-02-19 20:23:00+00:00
INFO:vectorbtpro.data.updater:New data has 15 rows from 2022-02-19 20:09:00+00:00 to 2022-02-19 20:23:00+00:00
INFO:vectorbtpro.utils.schedule_:Stopping schedule manager
- Run these two lines in a separate cell to see the updates in real time
- One frame in 250 milliseconds (i.e., 4 frames per second) and loop indefinitely
- Using DataUpdater.update_every
To stop earlier, simply interrupt the execution.
Hint
To run the job in the background, set in_background to True. The execution can then be manually stopped by calling ohlc_fig_updater.schedule_manager.stop().
After the data updater has finished running, we can access the entire data:
>>> ohlc_fig_updater.data.close
Open time
2022-02-19 20:09:00+00:00 40005.78
2022-02-19 20:10:00+00:00 40001.80
2022-02-19 20:11:00+00:00 40006.45
2022-02-19 20:12:00+00:00 40003.68
2022-02-19 20:13:00+00:00 40022.24
2022-02-19 20:14:00+00:00 40026.73
2022-02-19 20:15:00+00:00 40048.88
2022-02-19 20:16:00+00:00 40044.92
2022-02-19 20:17:00+00:00 40044.03
2022-02-19 20:18:00+00:00 40045.36
2022-02-19 20:19:00+00:00 40047.68
2022-02-19 20:20:00+00:00 40036.74
2022-02-19 20:21:00+00:00 40037.69
2022-02-19 20:22:00+00:00 40039.92
2022-02-19 20:23:00+00:00 40041.62
Freq: T, Name: Close, dtype: float64
And here's the produced GIF:

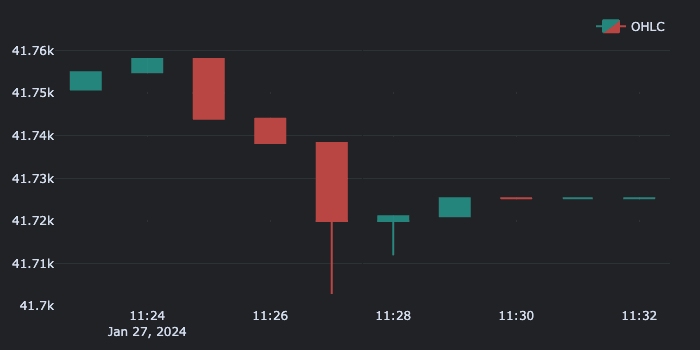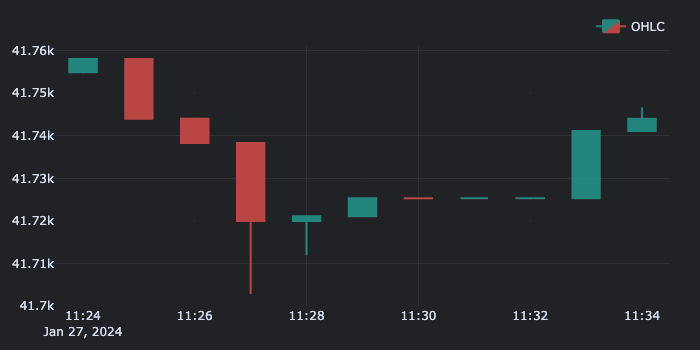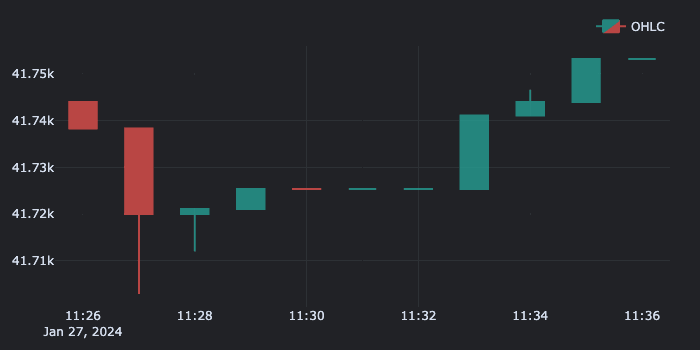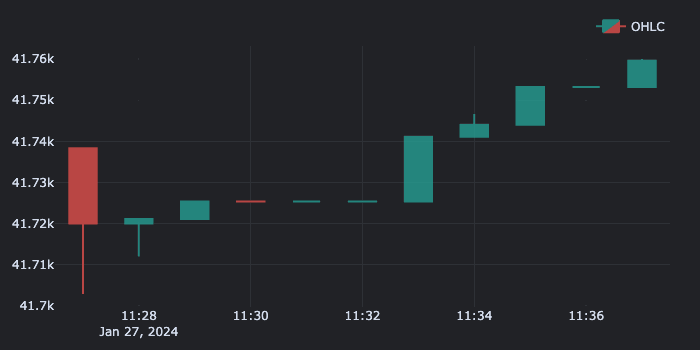
Hint
The smallest time unit of ScheduleManager is a second. For high-precision job scheduling, use a loop with a timer.
Saving¶
Regular updates with DataUpdater will keep the entire data in memory at any time. But what if we don't need to access the entire data? What if our main objective is to collect as much data as possible from an exchange and write each update directly to disk in a tabular format instead of processing it? This way, we could create one script that writes data updates to a file, and another script that regularly reads that file and performs a job. Moreover, this would make collecting data resilient to errors since we now persist every new bunch of data right away.
If this sounds good, then the DataSaver class is an ideal candidate for such sort of tasks. It subclasses the DataUpdater class and defines additional abstract methods DataSaver.init_save_data and DataSaver.save_data, which should take care of saving the existing data and each new bunch of data respectively into a file.
The workflow of DataSaver is simple. First, it takes a data instance data with some initially fetched data. Whenever we call DataSaver.update_every with init_save=True, it saves that data into a file using DataSaver.init_save_data. Once the existing data has been persisted to disk, with each new call of DataSaver.update, it pulls the next data update using Data.update with concat=False to avoid keeping the existing data in memory. It then calls DataSaver.save_data to append the new data to a file. This repeats either until the end of days or until the program gets interrupted by the user or system.
There are two preset subclasses of DataSaver:
- CSVDataSaver for writing data updates using Data.to_csv
- HDFDataSaver for writing data updates using Data.to_hdf
Let's pull 1-minute BTCUSDT data from Binance and write it to a CSV file, every 10 seconds:
>>> data = vbt.BinanceData.pull(
... "BTCUSDT",
... start="10 minutes ago UTC",
... end="now UTC",
... timeframe="1m"
... )
>>> csv_saver = vbt.CSVDataSaver(data)
>>> csv_saver.update_every(10, init_save=True) # (1)!
INFO:vectorbtpro.data.saver:Saved initial 10 rows from 2022-02-21 23:25:00+00:00 to 2022-02-21 23:34:00+00:00
INFO:vectorbtpro.utils.schedule_:Starting schedule manager with jobs [Every 10 seconds do update() (last run: [never], next run: 2022-02-22 00:34:55)]
INFO:vectorbtpro.data.saver:Saved 1 rows from 2022-02-21 23:34:00+00:00 to 2022-02-21 23:34:00+00:00
INFO:vectorbtpro.data.saver:Saved 2 rows from 2022-02-21 23:34:00+00:00 to 2022-02-21 23:35:00+00:00
INFO:vectorbtpro.data.saver:Saved 1 rows from 2022-02-21 23:35:00+00:00 to 2022-02-21 23:35:00+00:00
INFO:vectorbtpro.data.saver:Saved 1 rows from 2022-02-21 23:35:00+00:00 to 2022-02-21 23:35:00+00:00
INFO:vectorbtpro.data.saver:Saved 1 rows from 2022-02-21 23:35:00+00:00 to 2022-02-21 23:35:00+00:00
- Use
init_saveto instruct vectorbt to save the initial data before updating
Important
If the initial data isn't on disk yet, pass init_save=True to save it first. Otherwise, only updates that follow will be saved!
Note
Don't forget to set up logging as we did in the previous example to see log messages.
Let's interrupt the execution here and throw a look at the data in csv_saver:
INFO:vectorbtpro.utils.schedule_:Stopping schedule manager
>>> csv_saver.data.close
Open time
2022-02-21 23:35:00+00:00 37185.95
Name: Close, dtype: float64
As we can see, in contrast to the data updater we used previously, the data saver keeps only the latest bunch of received data in memory that is necessary for the next update. All the previously fetched data is now stored in a CSV file. Let's take a look:
>>> pd.read_csv("BTCUSDT.csv", index_col=0, parse_dates=True)["Close"] # (1)!
Open time
2022-02-21 23:25:00+00:00 37247.29
2022-02-21 23:26:00+00:00 37296.44
2022-02-21 23:27:00+00:00 37190.16
2022-02-21 23:28:00+00:00 37135.50
2022-02-21 23:29:00+00:00 37186.11
2022-02-21 23:30:00+00:00 37056.19
2022-02-21 23:31:00+00:00 37079.47
2022-02-21 23:32:00+00:00 37181.49
2022-02-21 23:33:00+00:00 37288.48
2022-02-21 23:34:00+00:00 37209.83
2022-02-21 23:34:00+00:00 37240.21
2022-02-21 23:34:00+00:00 37245.64
2022-02-21 23:35:00+00:00 37248.12
2022-02-21 23:35:00+00:00 37213.55
2022-02-21 23:35:00+00:00 37168.76
2022-02-21 23:35:00+00:00 37185.95
Name: Close, dtype: float64
- Use Pandas to see the file without post-processing
There are many duplicated index entries, how so? Remember that whenever we request an update, we not only try to fetch new data points but also to update the latest existing ones. When we request 10 updates during a single 1-minute candle, we will get 10 different data points with the same timestamp. Overriding any data point in a CSV file is very inefficient since you need to traverse the entire file just to remove a line. Thus, new data gets appended to a file as it is, and whenever we want to fetch the entire data, CSVData will remove any duplicates for us:
>>> vbt.CSVData.pull("BTCUSDT.csv").close
Open time
2022-02-21 23:25:00+00:00 37247.29
2022-02-21 23:26:00+00:00 37296.44
2022-02-21 23:27:00+00:00 37190.16
2022-02-21 23:28:00+00:00 37135.50
2022-02-21 23:29:00+00:00 37186.11
2022-02-21 23:30:00+00:00 37056.19
2022-02-21 23:31:00+00:00 37079.47
2022-02-21 23:32:00+00:00 37181.49
2022-02-21 23:33:00+00:00 37288.48
2022-02-21 23:34:00+00:00 37245.64
2022-02-21 23:35:00+00:00 37185.95
Freq: T, Name: Close, dtype: float64
To clean the CSV file from duplicates, read the data using CSVData and write it back:
>>> vbt.CSVData.pull("BTCUSDT.csv").to_csv()
>>> pd.read_csv("BTCUSDT.csv", index_col=0, parse_dates=True)["Close"]
Open time
2022-02-21 23:25:00+00:00 37247.29
2022-02-21 23:26:00+00:00 37296.44
2022-02-21 23:27:00+00:00 37190.16
2022-02-21 23:28:00+00:00 37135.50
2022-02-21 23:29:00+00:00 37186.11
2022-02-21 23:30:00+00:00 37056.19
2022-02-21 23:31:00+00:00 37079.47
2022-02-21 23:32:00+00:00 37181.49
2022-02-21 23:33:00+00:00 37288.48
2022-02-21 23:34:00+00:00 37245.64
2022-02-21 23:35:00+00:00 37185.95
Name: Close, dtype: float64
Info
The step above is optional and brings no big benefit other than disk space savings. You should perform it only occasionally, mainly when the CSV file is to be imported into another program for analysis.
The saving process can be resumed at any time:
>>> csv_saver.update_every(10) # (1)!
INFO:vectorbtpro.utils.schedule_:Starting schedule manager with jobs [Every 10 seconds do update() (last run: [never], next run: 2022-02-22 00:35:55)]
INFO:vectorbtpro.data.saver:Saved 1 rows from 2022-02-21 23:35:00+00:00 to 2022-02-21 23:35:00+00:00
INFO:vectorbtpro.data.saver:Saved 2 rows from 2022-02-21 23:35:00+00:00 to 2022-02-21 23:36:00+00:00
INFO:vectorbtpro.data.saver:Saved 1 rows from 2022-02-21 23:36:00+00:00 to 2022-02-21 23:36:00+00:00
INFO:vectorbtpro.utils.schedule_:Stopping schedule manager
- We don't need
init_savehere since this data is already on disk
Note
If the data provider offers only a limited time window of high-granular data, avoid stopping the saving process for a prolonged period of time, otherwise, the data will have blanks.
If we want to resume the saving process even after restarting the runtime, it's advisable to pickle and save the data saver to disk as well:
- Using Pickleable.save
We can then continue in a new runtime:
>>> import logging
>>> logging.basicConfig(level = logging.INFO)
>>> from vectorbtpro import *
>>> csv_saver = vbt.CSVDataSaver.load("csv_saver")
>>> csv_saver.update_every(10)
INFO:vectorbtpro.utils.schedule_:Starting schedule manager with jobs [Every 10 seconds do update() (last run: [never], next run: 2022-02-22 00:36:45)]
INFO:vectorbtpro.data.saver:Saved 1 rows from 2022-02-21 23:36:00+00:00 to 2022-02-21 23:36:00+00:00
INFO:vectorbtpro.data.saver:Saved 1 rows from 2022-02-21 23:36:00+00:00 to 2022-02-21 23:36:00+00:00
INFO:vectorbtpro.data.saver:Saved 2 rows from 2022-02-21 23:36:00+00:00 to 2022-02-21 23:37:00+00:00
INFO:vectorbtpro.utils.schedule_:Stopping schedule manager
How do we specify where exactly the data should be stored? DataSaver takes two arguments: save_kwargs and init_save_kwargs, which are forwarded to DataSaver.save_data and DataSaver.init_save_data respectively. For example, in CSVDataSaver, those keyword arguments are forwarded down to Data.to_csv. Thus, to change the directory path, we can simply do:
>>> csv_saver = vbt.CSVDataSaver(
... save_kwargs=dict(
... path_or_buf="data",
... mkdir_kwargs=dict(mkdir=True)
... )
... )
But this is not the only way to provide keyword arguments for saving. If we look closely at the arguments taken by the method DataUpdater.update_every, we would again see save_kwargs and init_save_kwargs, which are forwarded down to their methods. Those arguments have more priority and override the arguments with the same name passed to the constructor. This way, we can change the way the data is saved every time we resume the operation.
The same goes for HDFDataSaver.